ENGtoID
Overview
ENGtoID is a sequence-to-sequence neural machine translation system that translates English
sentences into Bahasa Indonesia using an LSTM encoder-decoder architecture.
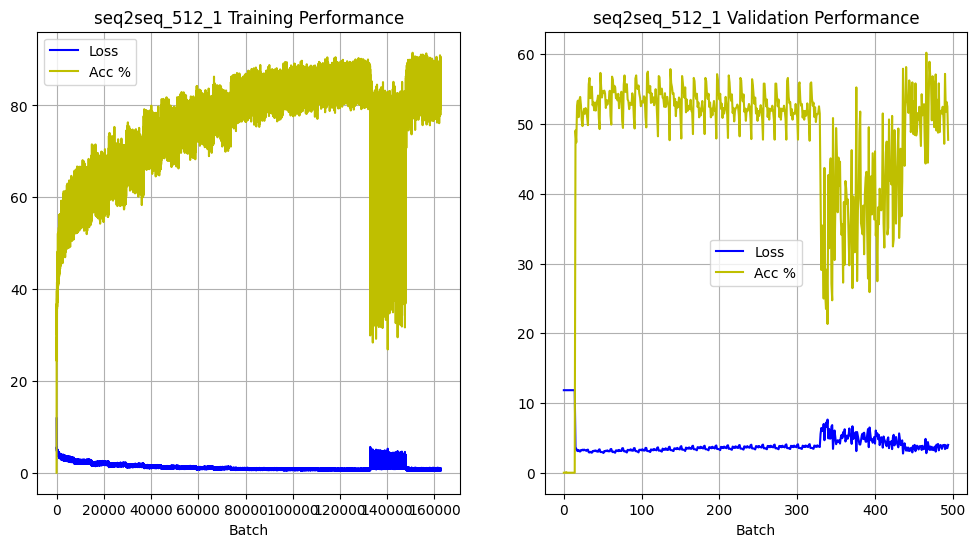
The plots show the training and validation performance of the model, demonstrating dips in accuracy
caused by experimental teacher forcing
The project was built as an end-to-end ML pipeline, covering dataset ingestion, cleaning,
vocabulary construction, training, evaluation, and error analysis at scale (~1M sentence pairs).
Pipeline Design
- Dataset download from HuggingFace (opus-Indonesian-to-English)
- Regex-based cleaning and filtering of noisy sentence pairs
- Vocabulary construction with ~250k combined tokens
- Token → index encoding with fixed special tokens
- PyTorch Dataset + DataLoader pipeline for training
Model Architecture
- Encoder: LSTM encodes English sentence into fixed context vector
- Decoder: autoregressive LSTM generates Indonesian tokens
- Loss: CrossEntropy with padding ignored
- Embedding size: 512 hidden dimensions
Training Strategy
- Trained on ~1M sentence pairs using RTX 4090 (cloud)
- Multi-phase learning rate schedule (from 1e-3 → 1e-5)
- Teacher forcing ratio gradually reduced to improve inference robustness
- Batch size adjustments to stabilise later-stage training
Key Engineering Decisions
- Adam optimizer for stable convergence on large-scale dataset
- Single-layer LSTM chosen over deeper stacked variants for capacity efficiency
- Explicit vocabulary control to ensure reproducibility
- Manual dataset pipeline for full training transparency
Evaluation
- Token-level accuracy used for training monitoring
- BLEU scoring used for validation evaluation
- Observed plateau after early training epochs (~50%+ accuracy)
- Validation set significantly smaller than training set (~0.2%)
Error Analysis
- Punctuation and sentence termination errors (
.,,,<EOS>) - Word order inconsistencies in generated output
- Difficulty with pronouns and function words
- Frequent
<UNK>substitutions for rare tokens
Limitations
- Whitespace tokenisation (no BPE / subword modelling)
- Vocab coupling to training artifacts (non-portable checkpoints)
- Weak validation split (~2k samples)
- LSTM architecture limits long-range dependency modelling
Future Improvements
- Replace tokenizer with BPE or SentencePiece
- Upgrade to Transformer architecture with attention
- Improve dataset splitting for proper generalisation metrics
- Add model checkpoint migration tooling